一、问题由来
SQL经过简化
1 | select * |
添加索引情况如下:
索引情况较乱
在查询一句Sql时,发现加limit与不加limit差异巨大
不加limit 5 查询时间如下(下图):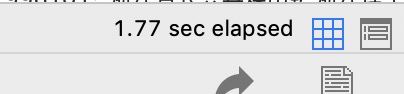
需要1.77秒
加limit 5 查询时间如下(下图):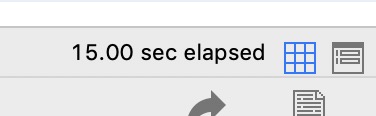
需要15.00秒
二、Mysql Explain分析
我们使用Mysql的Explanin来分析SQL语句,先来看下Explain的使用
点击学习MySQL 性能优化神器 Explain 使用分析
Explain输出格式
select_type
- SIMPLE, 表示此查询不包含 UNION 查询或子查询
- PRIMARY, 表示此查询是最外层的查询
- UNION, 表示此查询是 UNION 的第二或随后的查询
- DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
- UNION RESULT, UNION 的结果
- SUBQUERY, 子查询中的第一个 SELECT
- DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果
table
表示查询涉及的表或衍生表
type
- system:表中只有一条数据. 这个类型是特殊的 const 类型.
- const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可.
- eq_ref:此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高.
- ref:此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.
- range:表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.
- index:表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据.
- ALL:表示全表扫描, 这个类型的查询是性能最差的查询之一.
性能比较:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
possible_keys
表示 MySQL 在查询时, 能够使用到的索引. 注意, 即使有些索引在 possible_keys 中出现, 但是并不表示此索引会真正地被 MySQL 使用到. MySQL 在查询时具体使用了哪些索引, 由 key 字段决定.
key
此字段是 MySQL 在当前查询时所真正使用到的索引.
key_len
表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到.
- 字符串
char(n): n 字节长度
varchar(n): 如果是 utf8 编码, 则是 3 n + 2字节; 如果是 utf8mb4 编码, 则是 4 n + 2 字节. - 数值类型:
TINYINT: 1字节
SMALLINT: 2字节
MEDIUMINT: 3字节
INT: 4字节
BIGINT: 8字节 - 时间类型
DATE: 3字节
TIMESTAMP: 4字节
DATETIME: 8字节 - 字段属性: NULL 属性 占用一个字节. 如果一个字段是 NOT NULL 的, 则没有此属性.
rows
rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.
Extra
EXplain 中的很多额外的信息会在 Extra 字段显示, 常见的有以下几种内容:
- Using filesort
当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大. - Using index
“覆盖索引扫描”, 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错 - Using temporary
查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化.
下面尝试添加explain来分析SQL语句
不加limit 5 分析(下图):

简要分析(主要针对table为a):
- SIMPLE 得出该SQL不包含UNION语句和子查询
- type=ref显示该SQL包含较多join查询
- 可能用到的索引名称RYJobIDOne,RYJobIDTwo,RYJobIDThree,JobID,RStatus,但是实际只用到RStatus,RStatus为int型,为4字节,加上该字段可为NULL,再加1个字节,所以key_len=5字节
加limit 5 分析(下图):
简要分析(主要针对table为a):
- 与上述对比,差异主要在加了limit的语句实际使用的索引为RApplyDateTime。按上面的描述,datetime字段占用8字节,可为NULL再加1字节,还有2个字节去哪里死活查不到。也有可能是Mysql版本的愿原因,相同类型字段的占用字节数不同,此Mysql版本为5.5.52-MariaDB,这里可能datetime本身占用的是10字节。

总结:索引乱加导致的后果,谨慎添加索引!!!
三、索引使用优化
1、MySQL索引的类型
- 普通索引:这是最基本的索引,它没有任何限制,比如上文中为title字段创建的索引就是一个普通索引,MyIASM中默认的BTREE类型的索引,也是我们大多数情况下用到的索引。
- 唯一索引:索引列的值必须唯一,但允许有空值(注意和主键不同)。如果是组合索引,则列值的组合必须唯一,创建方法和普通索引类似。
- 全文索引(FULLTEXT)
- 单列索引、多列索引:多个单列索引与单个多列索引的查询效果不同,因为执行查询时,MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
- 组合索引(最左前缀):平时用的SQL查询语句一般都有比较多的限制条件,所以为了进一步榨取MySQL的效率,就要考虑建立组合索引。
例如针对这三个字段x1、x2、x3,建立一个组合索引。建立这样的组合索引,其实是相当于分别建立了下面两组组合索引:- x1,x2,x3
- x1,x2
- x1
注意:最左匹配原则
- 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
- =和in可以乱序
2、MySQL索引的优化
- 何时使用聚集索引或非聚集索引?
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
| 列经常被分组排序 | 使用 | 使用 |
| 返回某范围内的数据 | 使用 | 不使用 |
| 一个或极少不同值 | 不使用 | 不使用 |
| 小数目的不同值 | 使用 | 不使用 |
| 大数目的不同值 | 不使用 | 使用 |
| 频繁更新的列 | 不使用 | 使用 |
| 外键列 | 使用 | 使用 |
| 主键列 | 使用 | 使用 |
| 频繁修改索引列 | 不使用 | 使用 |
- 使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。 - 索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。 - like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。 - 不要在列上进行运算
存在and和or的组合时,Mysql会对SQL进行拆分,所以建立多个单或组合索引
例如:1
2
3
4
5
6
7
8
9
10select a.*
from a
left join b on a.RCheckEIDOne = b.EID
left join c on a.RCheckEIDTwo = c.EID
left join d on a.RCheckEIDThree = d.EID
where a.IsDelete = 0
and a.RGuidangYear is null
and (a.RCheckEIDOne = '11'
or a.RCheckEIDTwo = '22'
or a.RCheckEIDThree = '33')需要建立三个索引,如下图:

使用explain分析可得下图:
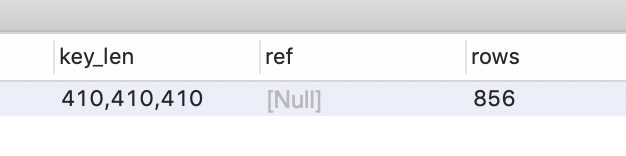
Mysql使用了3个索引来加快查询速度,Using union*3- NULL索引问题:
要尽可能地把字段定义为 NOT NULL,即使应用程序无须保存 NULL(没有值),也有许多表包含了可空列(Nullable Column)这仅仅是因为它为默认选项。除非真的要保存 NULL,否则就把列定义为 NOT NULL。
MySQL难以优化引用了可空列的查询,它会使索引、索引统计和值更加复杂。可空列需要更多的储存空间,还需要在MySQL内部进行特殊处理。当可空列被索引的时候,每条记录都需要一个额外的字节,还可能导致 MyISAM 中固定大小的索引(例如一个整数列上的索引)变成可变大小的索引。 即使要在表中储存「没有值」的字段,还是有可能不使用 NULL 的,考虑使用 0、特殊值或空字符串来代替它。 把 NULL 列改为 NOT NULL 带来的性能提升很小,所以除非确定它引入了问题,否则就不要把它当作优先的优化措施。然后,如果计划对列进行索引,就要尽量避免把它设置为可空,虽然在mysql里 Null值的列也是走索引的
总结:MySQL只对以下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引,不过除非是数据量真的很多,否则过多的使用索引也不是那么好玩的。
详细请仔细阅读
mysql索引的使用和优化

四、解决问题
我们回到开头的SQL
1 |
|
- 先删除原表的所有索引.
- 因为Mysql会选择并使用最优的一个索引(注意:仅使用一个,排除存在or),也就是根据explain的分析可得,key_len越大(不绝对,可以为NULL,会加1个字节),rows越小,这样SQL的执行效率最高。且我们尽量把where语句中的=、in操作操作放前面,其余的放后面(根绝最左匹配原则).
- 将IsDelete、RStatus、JobID字段尽可能设置为不为NULL.
- 建立联合索引,尝试建立以下索引(RStatus、IsDelete、JobID),如下图:

- 使用explain分析,如下图:

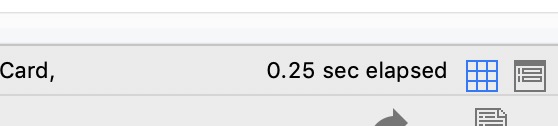
RStatus(int)4字节,IsDelete(int)4字节,JobID为varchar(50),50*4+2=202字节,总共4+4+202=210字节 - 再次运行带有limit的SQL语句,执行效率如下图:
五、总结
- 根据不同的SQL给表设置不同的索引,配合单列索引和所列索引,但是不要过多!
- 多多使用explain来分析!!
- 注意最左匹配原则!!!